Method
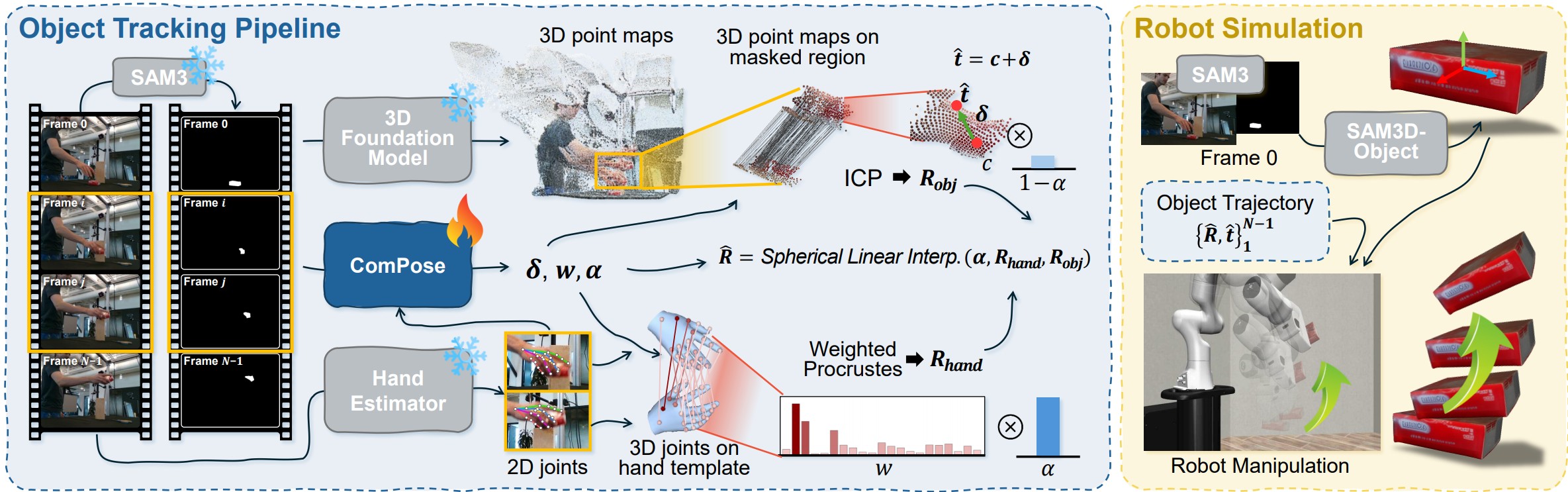
ComPose combines object and hand cues from foundation models within a unified tracking pipeline. It (i) adaptively selects informative hand joints, (ii) combines object- and hand-derived cues for motion estimation, and (iii) refines the resulting object motion using visible geometric evidence and a learned correction. Temporal consistency is enforced over both rotation and translation, producing stable 3D object trajectories without external smoothing.